Ansible: Fail When Changes Are Detected
Detecting changes and configuration drift with Semaphore UI and Ansible.
First off, a note: Although at the time of writing this, I work on Ansible at Red Hat, this post is written in a completely unofficial capacity. It should not be taken as official advice on how to use Ansible - only documenting a problem I had in my personal use of Ansible, and how I solved it.
With that out of the way...
Motivation
Ansible has long had a --check option to enable
check mode
which allows you to run a playbook without making changes (so long as the
modules you are using are written properly and respect check mode).
There's also a related --diff option, which, when combined with --check has
the effect of telling you "what would have changed" if you ran
ansible-playbook without --check.
I have recently been playing with the awesome, open source Semaphore UI project, which provides a web UI and REST API over the main Ansible Core command-line tool. It is similar in spirit to the Ansible AWX project, except simpler, not on indefinite release hiatus and responsive to its community (cough). Oh, and you can deploy it without Kubernetes - they ship RPMs, DEBs, Docker containers, etc. Nifty.
My Goal
What I want is this:
- I want to know about configuration drift on my servers
- I want to be alerted to it, if it happens, in the appropriate places (different places per project).
That's my goal.
What I'm (not) given
Let's talk about what Ansible and the third-party Semaphore UI tools both provide to help achieve the goal - and also what they lack.
Given: Scheduled Template Runs
Semaphore UI will let you schedule template runs. This is useful, because we can use this to run our playbook every day (for example), and see if anything changed.
Given: A (roundabout) way to run schedules specifically in check mode
Schedules unfortunately can NOT be set to run a playbook in check mode through
the UI. But we can work around that, because the template configuration UI lets
you add flags to the ansible-playbook call, so we can easily just add
--check (and --diff) ourselves:
NOT given: Notification routing
One lacking area in Semaphore UI is notifications. The notifications system it comes with is very lackluster. Notification settings are largely put in a single config file, and every project and template uses those same settings, so you can't readily say "I want alerts from this project to go to this Slack channel, and alerts from this other project to go to this other Slack channel," for example.
I opened a discussion and within 12 hours the maintainer responded, saying he'd gladly take a patch that revamps the notification system -- and this is something I'd love to try to tackle at some point, mostly as an excuse to learn Golang. But, anyway.
So, okay, not ideal. But we can kind of work around this... right?
Given: A REST API for task statuses
Semaphore UI provides a REST API, with endpoints that can tell you about the status of tasks (playbook runs) within a project.
So, theoretically, I could have some external system poll the API, check the
latest status of the right (scheduled) template which has --check in its
command-line arguments, and alert if the last run failed. This could be GitHub
Actions, Nagios, Checkmk, Jenkins, any kind of tool where you can schedule
periodic checks and alert on them.
But that only works if the playbook run actually fails...
NOT given: A built-in way to fail a playbook run if changes are detected
While Ansible has --check built in, it doesn't have a way to say "fail the
playbook run if any changes would be made," out of the box.
However, it does have a plugin system, and we can make use of the concept of callback plugins to help us accomplish this.
Callback plugins allow us to respond to "events" during the lifecycle of a playbook run in Ansible. Specifically, there is an event that gets triggered at the end of a playbook run, that in the normal case, is what triggers the stats to display. And to display the status correctly, we must know if anything changed - so this seems like a great place to hook into.
The Plan
So, how can we accomplish the goal?
We can design a callback plugin that will exit with a non-zero exit code (indiciating failure) if any changes are detected.
Then, we just:
- Create a Semaphore template that runs our playbook and adds
--check(and optionally--diff) to the command-line args, so they are always there. - Ensure our playbook run makes use of our custom callback plugin.
- Create a schedule to run this playbook template daily or as often as you wish.
- Set up some external tooling to ping the API and check the status of the last playbook run with your template ID in your project and alert if the playbook run failed.
The Callback Plugin
This is the plugin that I came up with. It's simple enough, just a few lines:
= 2.0
=
=
= False
return
=
return
Basically, what we do here is say, "hey, send me events!" and specifically, we
override the v2_playbook_on_stats() method which gets called at the end of
the playbook run.
We look for a specific extra_vars to be passed in (more on that in a second),
and if it is, we simply look through all the changed status, and if any of
them are above 0, we sys.exit(3).
This sys.exit() call will do just that. It will exit. This means, there could
be other callbacks that don't get called before we exit, depending on the
order in which the callback plugins run. In my case, this is fine, I am not
using any other callback plugins. But if you are, keep it in mind.
What I've done is created a plugins/callback directory in my Ansible project
directory, and I've put this plugin there
(plugins/callback/fail_on_changes.py). Then I've added this line to my
ansible.cfg also in the root of the Ansible project directory, in the
defaults section (create it - and the file - if they don't exist) to pick up
the new plugin:
[defaults]
plugins/callback
You can test it by running your playbook like normal, but add an extra
-e fail_on_changes to your ansible-playbook command. At the end, you should
either see a red "Changes detected" (and the exit code should be 3), or you
should see a green "No changes detected" (and the exit code should be 0).
Masking the behavior behind the -e fail_on_changes allows us to opt in to
the behavior and otherwise pretend it doesn't exist in the normal case.
The Semaphore Template
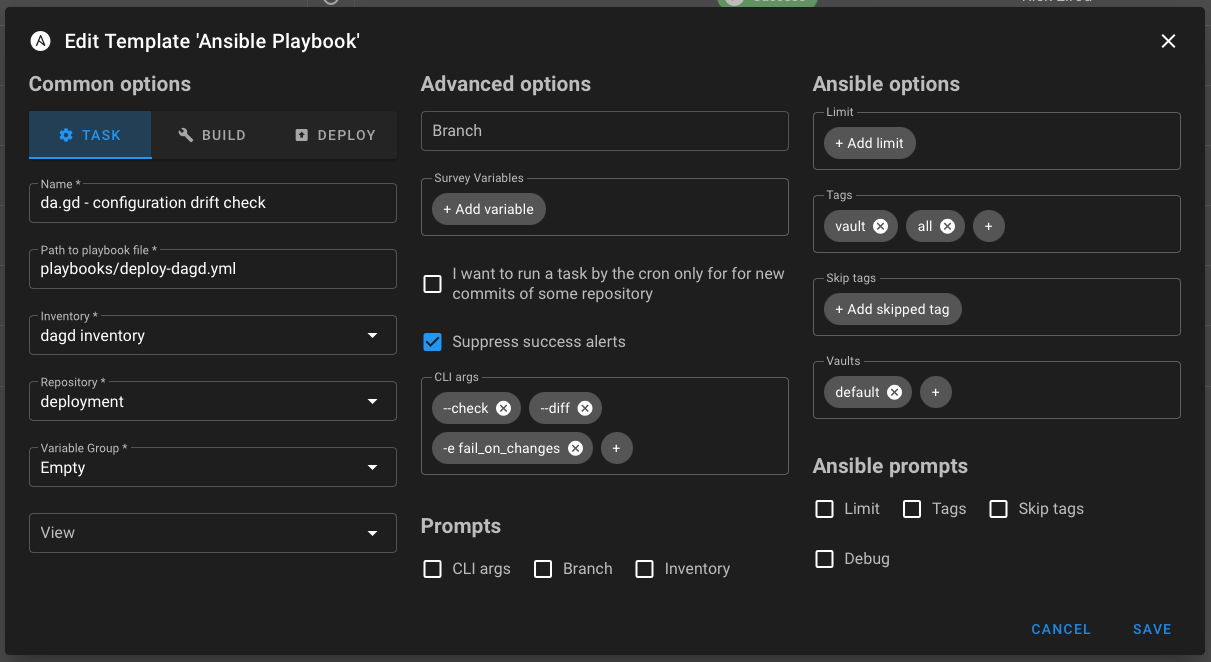
Using the deployment playbook for the da.gd server as an example, here's what my configuration drift template looks like in Semaphore. Particularly, note the CLI args section.
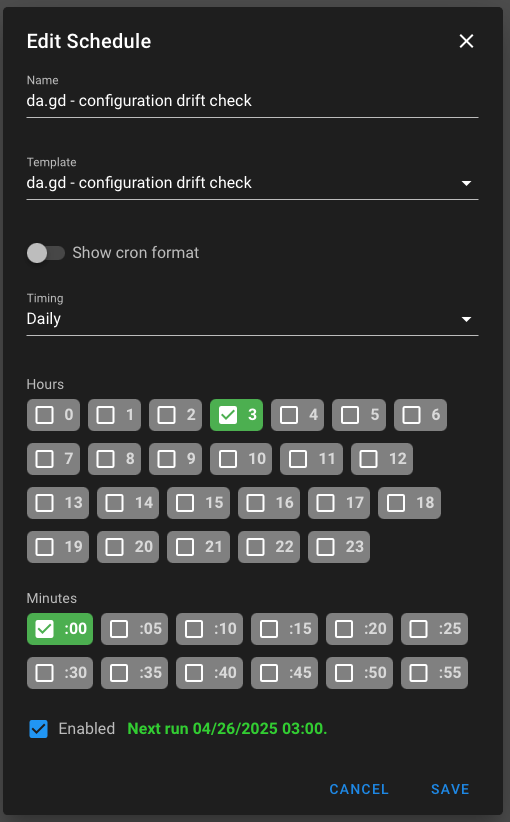
And here is the scheduler entry:
The Semaphore REST API
There is documentation on how to set up a token and access the Semaphore REST API.
Creating a token became much easier in version 2.14, which (as of this writing) is in Beta. It provides a UI for creating tokens easily!
Once you have a token, you can use it to check the
/api/project/PROJECT_ID/tasks/last endpoint, which will show the last 200
tasks (template runs) for the given PROJECT_ID.
You can write a short script or use jq to parse the JSON, look for the
template_id with the template you made above, and check the status of it. The
latest run will always be the first in the list of tasks returned from the
API.
Conclusion
And that's really all there is to it. It's a bit of a roundabout way to keep tabs on configuration drift, but it works. I've tied it into my existing monitoring systems, and have had no problems so far.
Using the callback plugin approach to return a failure exit code on changes is something that others might not have thought of, and I hadn't seen it done before, so I thought I would write up a short post here showing how it could be done.
Good luck, have fun, and happy automating!